One of the difficulties of starting a non-profit is finding donors and funding agencies. We’ve seen first hand the challenges involved! With so many different foundations with a wide variety of mission statements, how do we find one that is most closely aligned with our goals?
As statisticians and data scientists, we decided to tackle this problem using data. We collected a set of private foundation mission statements from GuideStar. And pre-processed the data into the following format:
library(tidyverse)
library(stringdist)
library(tidytext)
guidestar <- read_csv("guidestar_full.csv")
guidestar
# A tibble: 1,056 x 3
EIN Organization Mission
<chr> <chr> <chr>
1 91-1663… Bill & Melinda Gates Foundat… The foundation conducts all operations and g…
2 56-2618… BILL & MELINDA GATES FOUNDAT… Guided by the belief that every life has equ…
3 23-7093… John D. and Catherine T. Mac… The John D. and Catherine T. MacArthur Found…
4 91-0793… Casey Family Programs Casey Family Programs is the nation's larges…
5 65-0464… John S. and James L. Knight … Knight Foundation is a national foundation w…For this post, we’ll work to match this (fake) non-profit mission statement or query with possible donors.
We aim to promote awareness of serious heart conditions and work to provide treatment for those with heart disease, high blood pressure, diabetes, and other cardiovascular-related diseases who are unable to afford it.
query <- "We aim to promote awareness of serious heart conditions and work to provide treatment for those with heart disease, high blood pressure, diabetes, and other cardiovascular-related diseases who are unable to afford it."
We will now explore two methods for matching a non-profit mission statement to one of the mission statements from this dataset.
- We look for exact matches in words from the donor’s mission and the recipient’s mission using tidytext text manipulation routines.
- We use a word2vec representation model where words are represented by vectors containing some embedded information about it’s meaning.
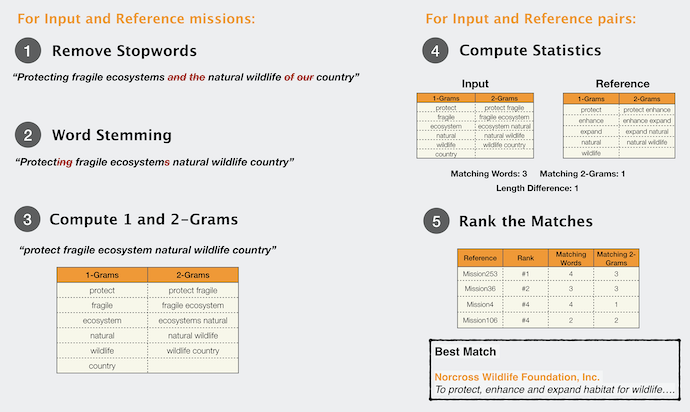
Let’s start with approach one. We’ll use tidytext and extract the words from the mission statements. We’ll do an anti_join operation on stop words. These are words such as articles “the”, “of”, etc. which have little relevant information in terms of statistical matching.
guidestar_words <- guidestar %>%
mutate(Mission = paste(Organization, Mission)) %>%
unnest_tokens(word, Mission, drop = FALSE) %>%
anti_join(get_stopwords()) %>%
add_count(Organization, word, sort = TRUE) %>%
bind_tf_idf(word, Organization, n)
guidestar_words %>% select(Organization, word, n, tf_idf) %>% sample_n(5)
# A tibble: 5 x 4
Organization word n tf_idf
<chr> <chr> <int> <dbl>
1 BELLWETHER FOUNDATION bellwether 2 0.228
2 Center for Cultural Judaism Inc can 1 0.0219
3 The Moore Foundation necessary 2 0.0186
4 Farm-to-Consumer Legal Defense Fund Foundation state 1 0.0439
5 JAYDEN LAMB MEMORIAL FOUNDATION jayden 2 0.522 Note that we’ve also
We’ll also include 2-grams – Using the built-in funcionality of tidytext to tokenize these 2-grams from each review.
guidestar_twograms <- guidestar_words %>%
select(EIN, Organization, word) %>%
group_by(Organization) %>%
summarise(Mission = paste(unique(word), collapse = " ")) %>%
unnest_tokens(twogram, Mission, token = "ngrams", n = 2)
guidestar_twograms %>% sample_n(5)
# A tibble: 5 x 2
Organization twogram
<chr> <chr>
1 DEANGELO WILLIAMS FOUNDATION focus children's
2 CHOSEN AND LOVED actively advocate
3 VOICE OF ELIJAH INC 12 nasb
4 Kimbell Art Museum contained follows
5 The Moore Foundation heart conditions We now perform the same routine on our query object from above, extracting words and 2-grams.
query_words <- query %>%
as.data.frame %>%
select(Query = 1) %>%
mutate(Query = as.character(Query)) %>%
unnest_tokens(word, Query) %>%
anti_join(stopwords)
query_twograms <- query_words %>%
summarise(Mission = paste(unique(word), collapse = " ")) %>%
unnest_tokens(twogram, Mission, token = "ngrams", n = 2)
Now that we have a similar table for the query mission, we can compare this table to the ones for all the donor missions and create a score to find the best matching donor mission!
The score is calculated as:
Score = MatchingWords + MatchingTwoGrams - LengthDiff + AverageTFIDF
where,
MatchingTwoGrams is the number of times the exact same
LengthDiff is the difference in the length of the two mission statements (penalizes it being longer than the foundation’s statement)
AverageTFIDF is the average
full_list <- query_twograms %>%
inner_join(guidestar_twograms) %>%
group_by(Organization, twogram) %>%
summarise(MatchingTwoGrams = n()) %>%
group_by(Organization) %>%
summarise(MatchingTwoGrams = sum(MatchingTwoGrams),
UniqueTwoGrams = length(unique(twogram))) %>%
full_join(
query_words %>%
inner_join(guidestar_words) %>%
group_by(Organization, word) %>%
summarise(MatchingWords = n(),
tf_idf = tf_idf[1],
Mission = Mission[1]) %>%
group_by(Organization) %>%
summarise(MatchingWords = sum(MatchingWords),
UniqueWords = length(unique(word)),
Mission = Mission[1],
LengthDiff = abs(nchar(query) - nchar(Mission[1])),
AverageTFIDF = mean(tf_idf),
MaxTFIDF = max(tf_idf))
)
full_ranks <- full_list %>%
mutate_if(is.numeric, function(.) (. - min(., na.rm = TRUE)) / (max(., na.rm = TRUE) - min(., na.rm = TRUE))) %>%
mutate(MatchingTwoGrams = ifelse(is.na(MatchingTwoGrams), 0, MatchingTwoGrams)) %>%
mutate(UniqueTwoGrams = ifelse(is.na(UniqueTwoGrams), 0, UniqueTwoGrams)) %>%
mutate(MatchingWords = ifelse(is.na(MatchingWords), 0, MatchingWords)) %>%
mutate(UniqueWords = ifelse(is.na(UniqueWords), 0, UniqueWords)) %>%
mutate(Score = MatchingWords + MatchingTwoGrams - LengthDiff + AverageTFIDF) %>%
arrange(desc(Score)) %>%
slice(1:5)
full_ranks %>%
select(Organization, Mission) %>%
as.data.frame
Using this ranking, our top 5 matching organizations are:
Organization
1 Rosenfeld Heart Foundation Inc
2 Blood Brothers Foundation
3 PULSE3 FOUNDATION
4 Israel at Heart
5 Robey Charitable TrustAnd their respective missions:
1. To Support Research In, And The Disseminatin And Publication Of Knowledge Concerning The Causes, Treatment And Prevention Of Diseases Of The Heart And Circulation.
2. Blood Brothers is dedicated to transforming the lives of individuals living with spinal cord injuries by restoring physical freedom, mobility, and independence.
3. To create a community that is healthy and vibrant by championing causes related to the education, prevention and treatment of cardiovascular-related disease.
4. To Promote Better Understanding Of Israel
5. The overall objective of our Trust is to help improve the conditions of all people.
Thus we have seen how a simple matching of words and
Leave a Reply
You must be logged in to post a comment.