The ongoing COVID-19 public health emergency has increased the urgency of data analysis and predictive analytics in helping to effectively combat the spread of the virus, and target regions of the world that are or will be most in need. At OAITI, we like so many others have been collecting data relating to the outbreak, and trying to use this data to inform better decision-making, from individual daily actions to public policy directives.
Recently, we came across a COVID-19 Chest X-ray Imagery Dataset on GitHub currently being aggregated. So far, this data contains a couple hundred x-ray images, and a label indicating the finding of the image. For example, here are two images from the dataset – The patient on the left tested positive for SARS, while the patient on the right tested positive for COVID-19:
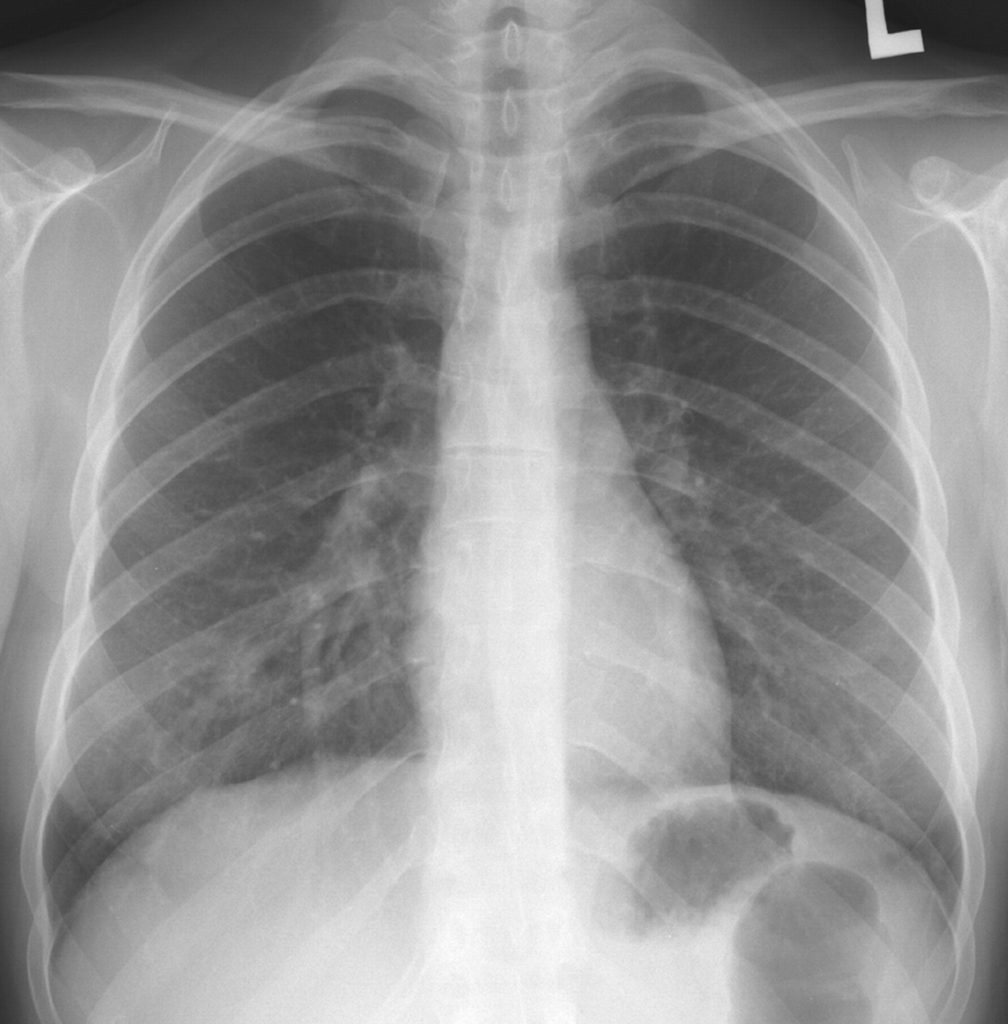
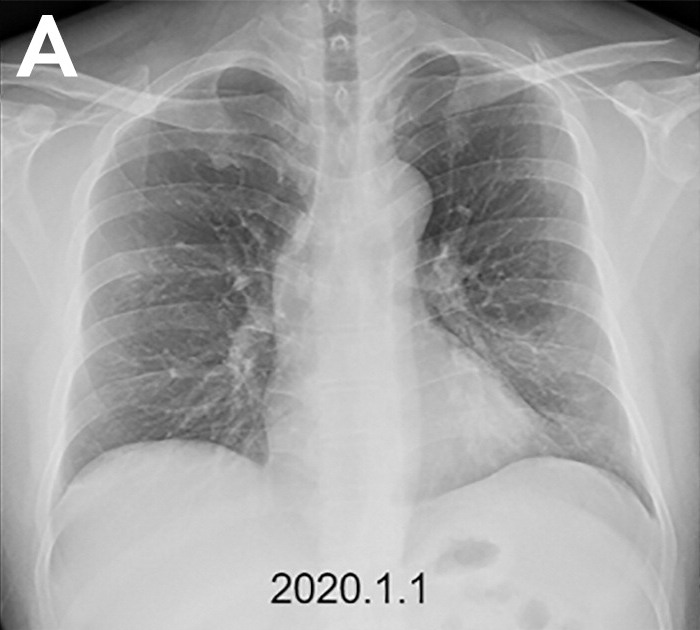
Along with the data, associated metadata is provided which includes demographic information about the patient, including their sex, age, and whether they ultimately survived. Here’s a small sample of the metadata, with the metadata corresponding to the two images from above in the first two rows (Note that we’ve collapsed several of the bacteria-based findings into a single category “Bacteria Induced” for ease of display):
| filename | finding | age | sex | survival |
| SARS-10-g04mr34g04a-Fig4a-day7.jpeg | SARS | 29 | F | Y |
| nCoV-radiol.2020 200269.fig1-day7.jpeg | COVID-19 | 42 | M | Y |
| all14238-fig-0002-m-d.jpg | COVID-19 | 36 | M | N |
| cavitating-pneumonia-4-day0-L.jpg | Bacteria Induced | 60 | M | Y |
Our goal will be to examine the raw image data to determine if there are any distinctive characteristics that we can extract in order to separate different types of infections. If successful, this would indicate the possibility of building more advanced models that can ingest X-ray images of patients in order to quickly assess the possibility that the patient shows signs of a particular virus present, including COVID-19.
The two techniques we will use are UMAP (Uniform Manifold Approximation and Projection), and PCA (Principal Components Analysis). Both of these techniques are dimension-reduction techniques, which aim to take large complex data (like these X-ray images) and reduce them to a smaller number of dimensions for visualization. To begin, we parse the metadata and collapse some of the findings as described:
# Read the COVID-19 Chest X-ray metadata
metadata <- read_csv("metadata.csv")
# Build a temporary dataset where we load each image in for processing
xrays_tmp <- metadata %>%
filter(modality == "X-ray") %>%
mutate(finding = fct_collapse(finding,
`COVID-19` = c("COVID-19", "COVID-19, ARDS"),
`Bacteria Induced` = c("E.Coli", "Klebsiella", "Chlamydophila",
"Legionella", "Streptococcus"))) %>%
unite(path, folder, filename, sep = "/") %>%
select(path, finding, age, sex, survival) %>%
rowwise() %>%
mutate(image = list(image_read(path)))
In order to perform UMAP and PCA, our data must have the same number of dimensions. Unfortunately, the X-ray images are of different formats, resolutions, and width-height ratios. We use the magick package in order to alleviate this. We first choose the smallest image in the dataset as a reference image. We then use magick to resize and reshape each image to match this dimensionality, which will allow us to bind all the images together in a consistent data frame for our visualization techniques.
# Get the smallest width and height contained within the dataset
im_data <- sapply(xrays_tmp$image, image_data)
dim_data <- sapply(im_data, dim)
width_low <- min(dim_data[2,])
height_low <- min(dim_data[3,])
# Build our dataset for processing
xrays <- xrays_tmp %>%
left_join(
tibble(
finding = sort(unique(xrays_tmp$finding)),
color = brewer.pal(length(unique(xrays_tmp$finding)), "Dark2")
)
) %>%
rowwise() %>%
mutate(
image = list(
image %>%
image_convert(colorspace = "gray") %>%
image_resize(paste0("!", width_low, "x", height_low))
))
# Get all the image data contained within the images and bind them
im_data <- lapply(xrays$image, image_data)
im_data_num <- lapply(im_data, as.numeric)
image_df <- do.call(rbind, im_data_num)
Finally, we can perform UMAP and PCA. In addition, we are going to process the original images in order to add a colored border that represents the type of finding that occurred in the patient. This will allow us to more easily visualize the resulting dimensionality reduction provided by UMAP and PCA, and assess whether there is evidence of separation between the different types of infections.
# Perform UMAP and PCA on the image pixels
image_umap <- umap(image_df, n_components = 2)
image_pca = prcomp(image_df)
# Append a border to the images for display
xrays_final <- xrays %>%
rowwise() %>%
mutate(
image = list(
image %>%
image_convert(colorspace = "rgb") %>%
image_border(color = color, geometry = "40x40")
)
)
# Write out the processed images to a new file for plotting
for (i in 1:nrow(xrays_final)) {
image_write(xrays_final$image[i][[1]], path = gsub("(.*)(.jpg|.jpeg|.png)", "\\1_processed\\2", xrays_final$path[i]))
}
# Build up the final PCA and UMAP data frames
final_data <- as.data.frame(image_pca$x[,1:2]) %>%
cbind(
as.data.frame(image_umap)
) %>%
cbind(
xrays_final %>%
select(-image) %>%
mutate(processed_path = gsub("(.*)(.jpg|.jpeg|.png)", "\\1_processed\\2", path))
) %>%
mutate(finding = factor(finding, levels = unique(finding))) %>%
arrange(finding)
Finally, we use ggplot2 to produce our visualizations. Because of the number of images, we’ve uploaded these in high-resolution, so please click on each image in order to drill down into the results.
We clearly see that the SARS-positive X-ray images have been separated well into their own regions of the 2-D plot display, suggesting that they exhibit characteristics that strongly differ from other types of infections. The COVID-19 positive images dominate the data, and span most regions of the display. We hope that as data continues to be collected in this repository, the separation continues to improve, given the implications this may have in terms of the feasibility of performant classification models.
More importantly, we look forward to doing our small part to help use data analysis for the good of society in these exceptionally trying times. We want to continue to show that data science has the power not just to uncover interesting patterns and insights, but to direct public policy and ultimately save lives. We will continue to strive to conduct analyses on COVID-19 as the situation unfolds.
2 Comments
Robert M Flight
So PCA is often used as a denoising algorithm with various types of image data via decomposition, keeping the top X components, and then back convert to make a clean(er) image. Would it be more useful to use PCA to remove noise like this, and then use other deep learning tools to carry out classification?
I do think it is cool that PCA *seems* to work on these regardless, although it is very hard to tell that from your current plots. Maybe remove the X-ray image from each point and replot?
Eric Hare
Thanks for the comment Robert! You’re right – We’re effectively performing this as a pre-modeling stage, for exploratory purposes, not (yet) with the intent of classification. When it comes time to actually differentiate the classes, we would use some deep learning technique to do so – UMAP or PCA might still be a component of that for the denoising as you said, but yeah, this was more as a preliminary look
Here is a version of the PCA plot with points instead of the X-ray images. I agree it seems to work well, particularly for SARS, where the majority are in their own cluster to the left of the overall mass:
https://oaiti.org/wp-content/uploads/2020/04/covid_pca_points.png