One of our fundamental goals of OAITI is to empower organizations, communities, and even individuals to collect and analyze their data. Data science as a field has been revolutionized by software which allows analyses to be conducted on personal computers. In most cases, this may not require much computational power – much of the work can be done on personal laptops.
Different organizations may be further along in their understanding of the power of data science. Some may be analyzing their data to help make decisions, some may be collecting their data without much corresponding analysis, and others still may not know how to start the data collection process. We were pleased to find that the Iowa Department of Education not only is collecting very useful educational data for Iowa schools, but is also making them publicly available on their website.
To begin to work with this data, we used R and the associated package rvest to write a web-scraping routine to automatically pull all the bullying data since 2013, bind it together, clean it up, and create a dataset more suitable for analysis. We’ve made the cleaned version of that data available here – The data includes information on the number of reported bullying incidents overall, and of various types, in each district, in each year from 2013 to 2016. It also includes information on the county with which the district is located, as well as the enrollment of that district in the particular year. A sample of the data is given below:
| District Name | County | Year | Enrollment | Incidents |
|---|---|---|---|---|
| Adair-Casey | Guthrie | 2016 | 273 | 0 |
| Adel DeSoto Minburn | Dallas | 2016 | 1679 | 19 |
| AGWSR | Hardin | 2016 | 553 | 5 |
| A-H-S-T | Pottawattamie | 2016 | 626 | 4 |
| Akron Westfield | Plymouth | 2016 | 574 | 13 |
| Albert City-Truesdale | Buena Vista | 2016 | 86 | 0 |
| Albia | Monroe | 2016 | 1169 | 4 |
| Alburnett | Linn | 2016 | 603 | 0 |
| Alden | Hardin | 2016 | 226 | 0 |
| Algona | Kossuth | 2016 | 1406 | 9 |
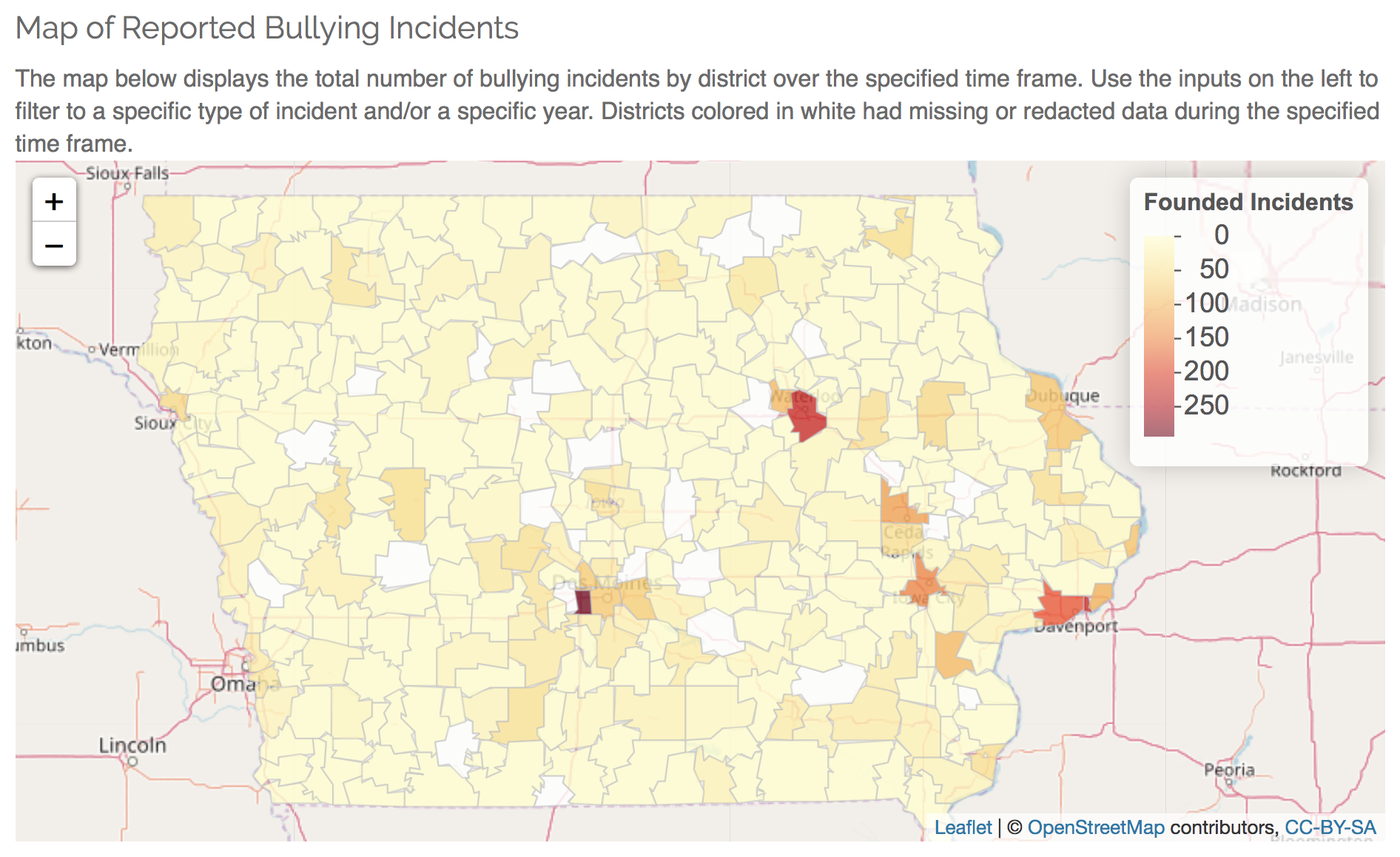
Using this data, we created a web application using the Shiny framework. Shiny allows the results of an R analysis to be turned into an interactive application. With the help of some additional R packages such as leaflet, the app allows users to visually explore the incidents of bullying in each Iowa school district by zooming and panning a map of the state. Some options for configuration are provided as well. The user can select a particular year, and/or a particular incident type. The user can choose to scale the number of incidents in the selected timeframe by the enrollment of that district. Lastly, a statistical model is provided. The model is a simple linear regression of the number of incidents of the type selected over the 4 year period from 2013 to 2016. We would like to make the caveat clear that with such limited data, the results of this model should not be taken too seriously. Nonetheless, it can help see districts which have had an increasing or decreasing trend in incidents over the four year period.
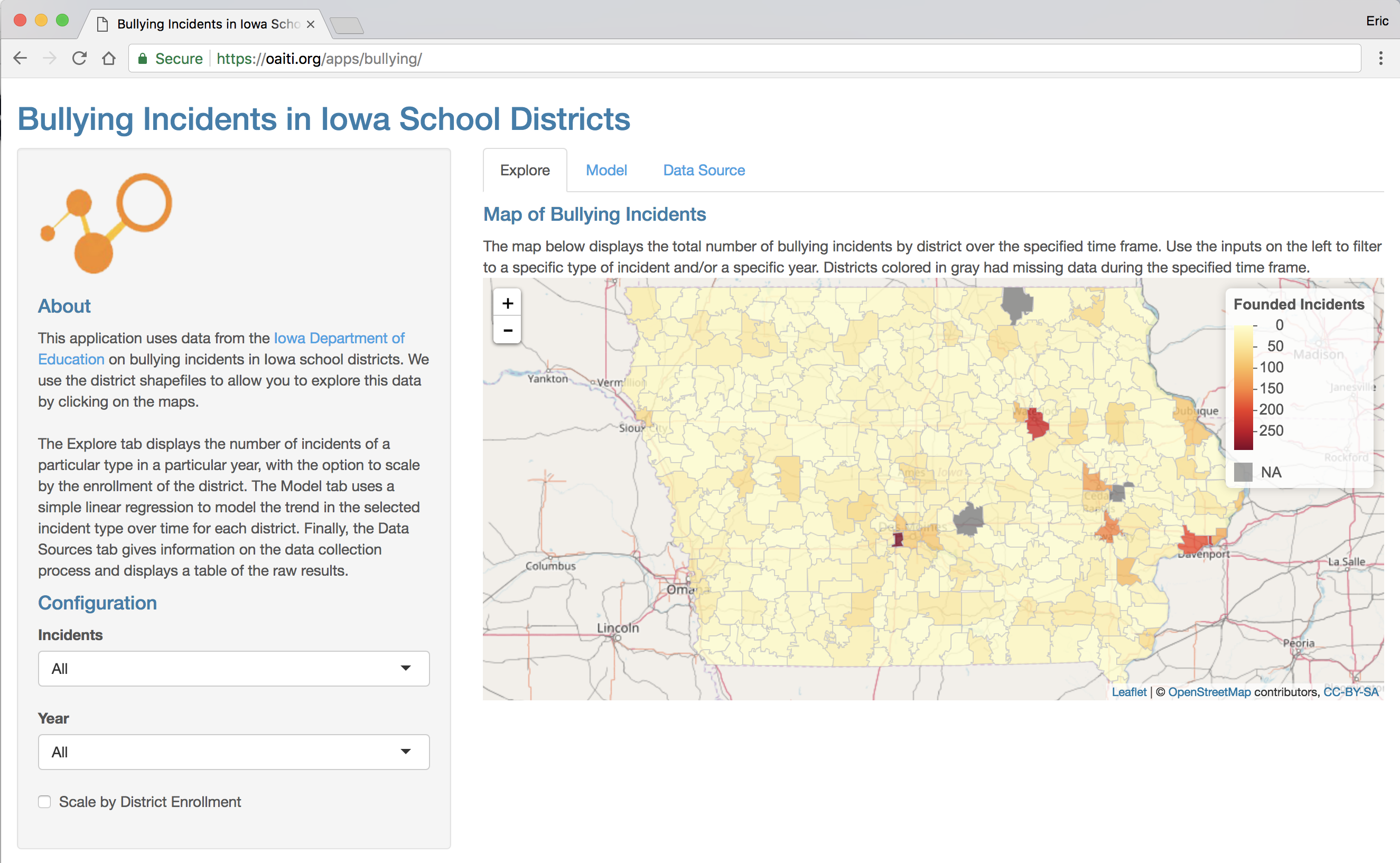
The app is available at the following URL: https://oaiti.org/apps/bullying/ – Feel free to explore the data yourself. A modern web browser, such as the latest version of Google Chrome, Mozilla Firefox, or Microsoft Edge is required. The full source code for the scraping routine, as well as the application, is available on our GitHub Page.
Leave a Reply
You must be logged in to post a comment.