There are many instances where we find a list of useful items or a table placed on a web page that can help us enhance our analysis or even form the data for our projects. Most often, copy pasting off of the web page does not work very well and can take hours to complete. This is the situation we were faced with when trying to a list of organizations for one of our clients’ projects.
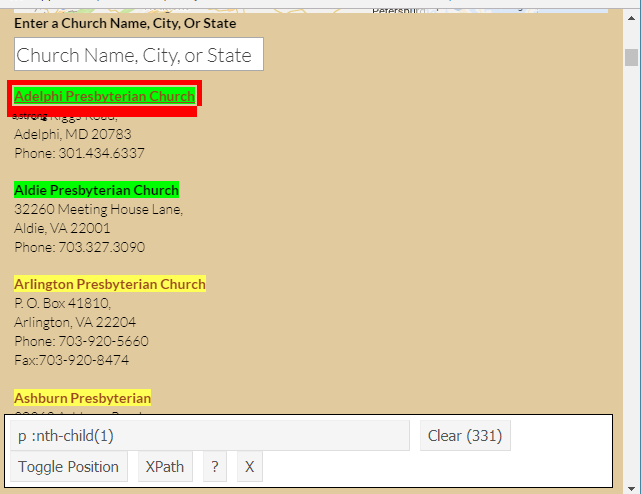
We are working with Dave Grace, who is the Director of Christian education at a prominent church in Washington DC, in order to create a program to assess the energy efficiency of churches in DC, Maryland and Virginia. In the process of planning this program, one task was to get a list of churches in these areas from the National Capital Presbytery website. The site has the list of churches in the following format: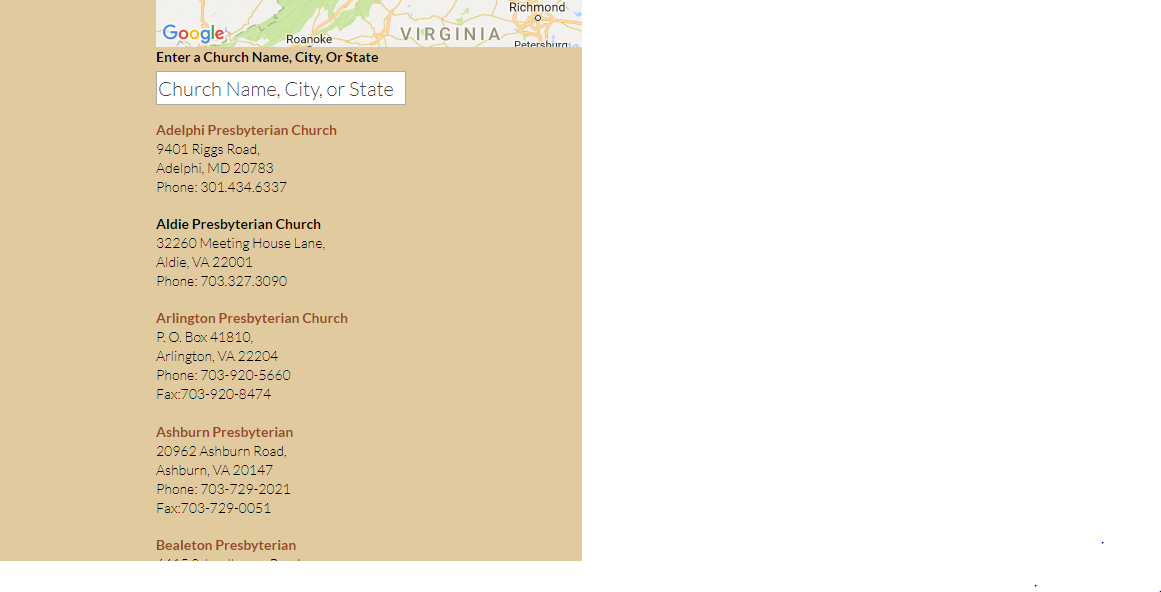
The churches are listed out alphabetically on the website as links with the address and phone number as text below each link. In this post we describe the steps to go about creating a routine for scraping such data from a website.
Calling libraries for web scraping
The first thing we do is to load the necessary packages required for webscraping in R. We use the rvest package for scraping and stringr to clean the data.
library(rvest)
library(stringr)
Accessing relevant data
We then define the url containing the information we need, and read_html() function reads in the url and returns the information as an xml document.
First we want to retrieve the church names from the page. In order to do this we need to pull out the tags/ elements /nodes containing the church name in the XML. The function html_nodes() helps us do this, and we need to pass in the element name, which can be retrieved using a CSS selector tool called SelectorGadget. It can easily be installed as an extension on chrome browsers. In order to use it, we go to the url, click on the SelectorGadget icon and then right click on the element that we want to pull out. The box to the bottom right of your browser shows the selector. Right clicking again can deselect the element. We discover that the selector is called “p :nth-child(1)” for the church names, and this is passed into the function as – html_nodes(“p :nth-child(1)”)
Once the nodes/elements are accessed using html_nodes() function, the actual content is retrieved using html_text().
url <- "https://www.thepresbytery.org/about-us/churches/alphabetical-church-list"
church_names_temp <- url %>%
read_html() %>%
html_nodes("p :nth-child(1)") %>%
html_text()
Now we move on to scrape the actual contact information for each church. The contacts paragraph is selected using SelectorGadget again which gives us the selector name as “.church-info p”
church_info_temp <- url %>%
read_html() %>%
html_nodes(".church-info p") %>%
html_text()
Data Cleaning
This part is specific to the kind of resulting text your scraping retrieves. We faced the issues of having blank rows/churches and duplicated rows for each church, that need to be removed.
# Remove blanks
church_names <- church_names_temp[church_names_temp != ""]
# We notice all names are duplicated
names_table <- table(church_names)
# A couple of Churches have the same name (seen as 4 duplicates) which we do not want to remove, save these
dont_remove <- names(names_table)[names_table == 4]
church_names <- church_names[!duplicated(church_names)]
church_names <- sort(c(church_names, dont_remove))
Splitting the paragraphs of content
Regular expressions are useful in pulling out the appropriate parts from the messy text containing escape sequences. In this case, we needed to clean up the text and extract the phone numbers, addresses and state zip codes separately to put them in separate columns.
# separate on the carriage returns
church_info_split <- strsplit(church_info_temp, "\n")
# some phone numbers had ".", some had "-" separators
phone_numbers <- sapply(church_info_split, function(x) {
gsub("\\.", "-", gsub(".*Phone: ([0-9]+[.-][0-9]+[.-][0-9]+).*", "\\1", paste(x, collapse = " ")))
})
fax_numbers <- sapply(church_info_split, function(x) {
gsub("\\.", "-", gsub(".*Fax:([0-9]+[.-][0-9]+[.-][0-9]+).*", "\\1", paste(x, collapse = " ")))
})
fax_numbers[nchar(fax_numbers) > 12] <- NA
addresses <- sapply(church_info_split, function(x) {
gsub(" ", " ", str_trim(gsub("\t", "", gsub("(.*)Phone:.*", "\\1", paste(x, collapse = " ")))))
})
addresses_split <- strsplit(addresses, ", ")
state_zip <- sapply(addresses_split, function(x) { x[length(x)] })
state_zip_split <- strsplit(state_zip, " ")
final_zips <- sapply(state_zip_split, `[`, 2)
final_states <- sapply(state_zip_split, `[`, 1)
city <- sapply(addresses_split, function(x) { x[length(x) - 1] })
addresses_temp <- sapply(addresses_split, function(x) {
return(str_trim(paste(x[1:(length(x) - 2)], collapse = " ")))
})
Final Dataset!
The individual vectors of data are finally merged as columns in a dataframe. This can be written onto disk with a write.csv()
final_df <- data.frame(
Name = church_names,
Address = addresses_temp,
City = city,
State = final_states,
Zip = final_zips,
Phone = phone_numbers,
Fax = fax_numbers
)
head(final_df)
## Name Address City
## 1 Adelphi Presbyterian Church 9401 Riggs Road Adelphi
## 2 Aldie Presbyterian Church 32260 Meeting House Lane Aldie
## 3 Arlington Presbyterian Church P. O. Box 41810 Arlington
## 4 Ashburn Presbyterian 20962 Ashburn Road Ashburn
## 5 Bealeton Presbyterian 6415 Schoolhouse Road Bealeton
## 6 Berwyn Presbyterian 6301 Greenbelt Road College Park
## State Zip Phone Fax
## 1 MD 20783 301-434-6337 <NA>
## 2 VA 22001 703-327-3090 <NA>
## 3 VA 22204 703-920-5660 703-920-8474
## 4 VA 20147 703-729-2021 703-729-0051
## 5 VA 22712-0166 540-439-2375 <NA>
## 6 MD 20740 301-474-7573 <NA>